AutoEncoder vs Variant AutoEncoder
AutoEncoder vs Variant AutoEncoder
조대협 (http://bcho.tistory.com)
Abnormal
AutoEncoder는 입력값을 기반으로 여기서 특징을 뽑아내고, 뽑아낸 특징으로 다시 원본을 재생하는 네트워크이다. 이미지 합성이나 압축, Abnormal Detection 등 여러 유스케이스에 사용이 될 수 있지만, 특히 추출된 특징 (latent coding)은 데이타의 특징을 이해하는데도 유용하게 사용될 수 있다.
이 글에서는 AutoEncoder와 요금 각광 받는 VAE (Variant Auto Encoder) 의 차이를 알아보고 특히 latent coding의 값이 어떻게 다르게 표현되며, 어떤 의미를 가지는지에 대해서 이해한다.
일반 오토 인코더의 모양은 다음과 같다.

<그림 AutoEncoder의 구조>
출처 : https://excelsior-cjh.tistory.com/187
입력값 x로 부터 추출된 특징을 latent code z 라고 하는데,
이를 조금 더 이해하기 쉽게 표현해보면 다음과 같다.

<그림. AutoEncode의 latent code z 표현 방식 비교>
출처 : https://www.jeremyjordan.me/variational-autoencoders/
위의 그림은 오토 인코더를 이용해서 특징을 추출한 결과로 6개의 특징을 추출하였는데, 추출된 특징 latent code z는 특정 숫자값을 갖는다.
VAE는 이 latent code z의 값을 하나의 숫자로 나타내는 것이 아니라 가우시안 확률 분포에 기반한 확률값 (값의 범위)로 나타낸다.
아래 그림은 오토 인코더와 VAE에서 latent code z를 표현하는 방법을 설명한 것인데

<그림. AutoEncoder와 VAE의 latent code z 표현 방식 비교>
출처 : https://www.jeremyjordan.me/variational-autoencoders/
얼굴의 특징을 추출했다고 했을때 좌측은 오토인코더로 하나의 숫자로 특징을 표현하였고, 우측은 가우시안 확률 분포로 특징을 표현하였다. (확률값으로) 그래서 네트워크의 모양을 보면 다음과 같다.

<그림. VAE 구조>
출처 : https://excelsior-cjh.tistory.com/187
AutoEncoder latent coding 값이 single value z라면, VAE는 latent coding z를 가우시안 분포로 나타내기 위해서 평균과, 분산값으로 나타낸다.
AutoEncoder와 VAE의 latent space를 시각화 해보면 다음과 같은 차이를 발견할 수 있다. 아래 그림은 4 dimension latent space를 PCA(차원감소기법)을 통해서 2차원으로 변환한후 시각화 한 내용이다.
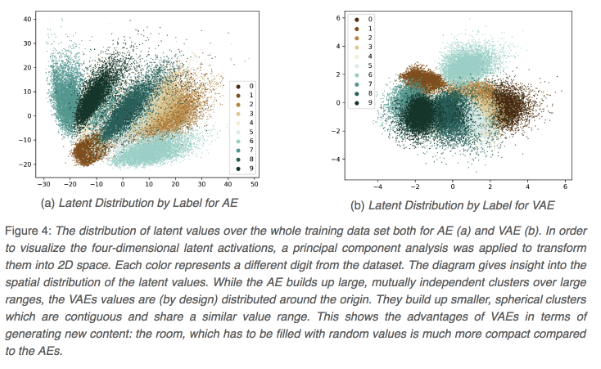
<그림. AE vs VAE의 latent space 비교>
출처 : https://thilospinner.com/towards-an-interpretable-latent-space/
MNIST에 대한 latent space인데, 각 점의 색깔은 0~9 숫자(이미지 라벨)을 표현한다.
좌측의 AE의 latent space는 군집이 넓게 퍼져있고, 중심점을 기반으로 잘 뭉치지 않는데 반해서 VAE는 중심점을 기반으로 좀더 컴팩트하게 잘 뭉쳐지는 것을 볼 수 있다. 그래서 원본 데이타를 재생하는데, AE에 비해 장점이 많고, latent space를 통해서 데이타의 군집을 파악하는데도 군집 강도가 높기 때문에 데이타의 특징을 파악하는데 좀더 유리하다.
참고 :