연예인 얼굴 인식 모델을 만들어보자 - #1. 학습 데이타 준비하기
연예인 얼굴 인식 서비스를 만들어보자 #1 - 데이타 준비하기
CNN 에 대한 이론 공부와 텐서 플로우에 대한 기본 이해를 끝내서 실제로 모델을 만들어보기로 하였다.
CNN을 이용한 이미지 인식중 대중적인 주제로 얼굴 인식 (Face recognition)을 주제로 잡아서, 이 모델을 만들기로 하고 아직 실력이 미흡하여 호주팀에서 일하고 있는 동료인 Win woo 라는 동료에게 모델과 튜토리얼 개발을 부탁하였다.
이제 부터 연재하는 연예인 얼굴 인식 서비스는 Win woo 가 만든 코드를 기반으로 하여 설명한다. (코드 원본 주소 : https://github.com/wwoo/tf_face )
얼굴 데이타를 구할 수 있는곳
먼저 얼굴 인식 모델을 만들려면, 학습을 시킬 충분한 데이타가 있어야 한다. 사람 얼굴을 일일이 구할 수 도 없고, 구글이나 네이버에서 일일이 저장할 수 도 없기 때문에, 공개된 데이타셋을 활용하였는데, PubFig (Public Figures Face Database - http://www.cs.columbia.edu/CAVE/databases/pubfig/) 를 사용하였다.

이 데이타셋에는 약 200명에 대한 58,000여장의 이미지를 저장하고 있는데, 이 중의 일부만을 사용하였다.
Download 페이지로 가면, txt 파일 형태 (http://www.cs.columbia.edu/CAVE/databases/pubfig/download/dev_urls.txt) 로 아래와 같이
Abhishek Bachan 1 http://1.bp.blogspot.com/_Y7rzCyUABeI/SNIltEyEnjI/AAAAAAAABOg/E1keU_52aFc/s400/ash_abhishek_365x470.jpg 183,60,297,174 f533da9fbd1c770428c8961f3fa48950
Abhishek Bachan 2 http://1.bp.blogspot.com/_v9nTKD7D57Q/SQ3HUQHsp_I/AAAAAAAAQuo/DfPcHPX2t_o/s400/normal_14thbombaytimes013.jpg 49,71,143,165 e36a8b24f0761ec75bdc0489d8fd570b
Abhishek Bachan 3 http://2.bp.blogspot.com/_v9nTKD7D57Q/SL5KwcwQlRI/AAAAAAAANxM/mJPzEHPI1rU/s400/ERTYH.jpg 32,68,142,178 583608783525c2ac419b41e538a6925d
사람이름, 이미지 번호, 다운로드 URL, 사진 크기, MD5 체크섬을 이 필드로 저장되어 있다.
이 파일을 이용하여 다운로드 URL에서 사진을 다운받아서, 사람이름으로된 폴더에 저장한다.
물론 수동으로 할 수 없으니 HTTP Client를 이용하여, URL에서 사진을 다운로드 하게 하고, 이를 사람이름 폴더 별로 저장하도록 해야 한다.
HTTP Client를 이용하여 파일을 다운로드 받는 코드는 일반적인 코드이기 때문에 별도로 설명하지 않는다.
본인의 경우에는 Win이 만든 https://github.com/wwoo/tf_face/blob/master/tf/face_extract/pubfig_get.py 코드를 이용하여 데이타를 다운로드 받았다.
사용법은 https://github.com/wwoo/tf_face 에 나와 있는데,
$> python tf/face_extract/pubfig_get.py tf/face_extract/eval_urls.txt ./data
를 실행하면 ./data 디렉토리에 이미지를 다운로드 받아서 사람 이름별 폴더에 저장해준다.
evals_urls.txt에는 위에서 언급한 dev_urls.txt 형태의 데이타가 들어간다.

사람 종류가 너무 많으면 데이타를 정재하는 작업이 어렵고, (왜 어려운지는 뒤에 나옴) 학습 시간이 많이 걸리기 때문에, 약 47명의 데이타를 다운로드 받아서 작업하였다.
학습 데이타 준비에 있어서 경험
쓰레기 데이타 골라내기
데이타를 다운받고 나니, 아뿔사!! PubFig 데이타셋이 오래되어서 없는 이미지도 있고 학습에 적절하지 않은 이미지도 있다.

주로 학습에 적절하지 않은 데이타는 한 사진에 두사람 이상의 얼굴이 있거나, 이미지가 사라져서 위의 우측 그림처럼, 이미지가 없는 형태로 나오는 경우인데, 이러한 데이타는 어쩔 수 없이 눈으로 한장한장 다 걸러내야만 했는데, 이런 간단한 데이타 필터링 처리는 Google Cloud Vision API를 이용하여, 얼굴이 하나만 있는 사진만을 사용하도록 하여 필터링을 하였다.
학습 데이타의 분포
처음에 학습을 시작할때, 분류별로 데이타의 수를 다르게 하였다. 어렵게 모은 데이타를 버리기가 싫어서 모두 다 넣고 학습 시켰는데, 그랬더니 학습이 쏠리는 현상이 발생하였다.
예를 들어 안젤리나 졸리 300장, 브래드피트 100장, 제시카 알바 100장 이런식으로 학습을 시켰더니, 이미지 예측에서 안젤리나 졸리로 예측하는 경우가 많아졌다. 그래서 학습을 시킬때는 데이타수가 작은 쪽으로 맞춰서 각 클래스당 학습 데이타수가 같도록 하였다. 즉 위의 데이타의 경우에는 안젤리나 졸리 100장, 브래드피트 100장, 제시카 알바 100장식으로 데이타 수를 같게 해야했다.
라벨은 숫자로
라벨의 가독성을 높이기 위해서 라벨을 영문 이름으로 사용했는데, CNN 알고리즘에서 최종 분류를 하는 알고리즘은 softmax 로 그 결과 값을 0,1,2…,N식으로 라벨을 사용하기 때문에, 정수형으로 변환을 해줘야 하는데, 텐서 플로우 코드에서는 이게 그리 쉽지않았다. 그래서 차라리 처음 부터 학습 데이타를 만들때는 라벨을 정수형으로 만드는것이 더 효과적이다
얼굴 각도, 표정,메이크업, 선글라스 도 중요하다
CNN 알고리즘을 마법처럼 생각해서였을까? 데이타만 있다면 어떻게든 학습이 될 줄 알았다. 그러나 얼굴의 각도가 많이 다르거나 표정이 심하게 차이가 난 경우에는 다른 사람으로 인식이 되기 때문에 가능하면 비슷한 표정에 비슷한 각도의 사진으로 학습 시키는 것이 정확도를 높일 수 있다.

얼굴 각도의 경우 구글 클라우드 VISION API를 이용하면 각도를 추출할 수 있기 때문에 20도 이상 차이가 나는 사진은 필터링 하였고, 표정 부분도 VISION API를 이용하면 감정도를 분석할 수 있기 때문에 필터링이 가능하다. (아래서 설명하는 코드에서는 감정도 분석 부분은 적용하지 않았다)
또한 선글라스를 쓴 경우에도 다른 사람으로 인식할 수 있기 때문에 VISION API에서 물체 인식 기능을 이용하여 선글라스가 검출된 경우에는 학습 데이타에서 제거하였다.
이외에도 헤어스타일이나 메이크업이 심하게 차이가 나는 경우에는 다른 사람으로 인식되는 확률이 높기 때문에 이런 데이타도 가급적이면 필터링을 하는것이 좋다.
웹 크라울링의 문제점
데이타를 쉽게 수집하려고 웹 크라울러를 이용해서 구글 이미지 검색에서 이미지를 수집해봤지만, 정확도는 매우 낮게 나왔다.
https://www.youtube.com/watch?v=k5ioaelzEBM
<그림. 설현 얼굴을 웹 크라울러를 이용하여 수집하는 화면>
아래는 웹 크라울러를 이용하여 EXO 루한의 사진을 수집한 결과중 일부이다.

웹크라울러로 수집한 데이타는, 앞에서 언급한 쓰레기 데이타들이 너무 많다. 메이크업, 표정, 얼굴 각도, 두명 이상 있는 사진들이 많았고, 거기에 더해서 그 사람이 아닌 사람의 얼굴 사진까지 같이 수집이 되는 경우가 많았다.
웹 크라울링을 이용한 학습 데이타 수집은 적어도 얼굴 인식용 데이타 수집에 있어서는 좋은 방법은 아닌것 같다. 혹여나 웹크라울러를 사용하더라도 반드시 수동으로 직접 데이타를 검증하는 것이 좋다.
학습 데이타의 양도 중요하지만 질도 매우 중요하다
아이돌 그룹인 EXO와 레드벨벳의 사진을 웹 크라울러를 이용해서 수집한 후에 학습을 시켜보았다. 사람당 약 200장의 데이타로 8개 클래스 정도를 테스트해봤는데 정확도가 10%가 나오지를 않았다.
대신 데이타를 학습에 좋은 데이타를 일일이 눈으로 확인하여 클래스당 30장 정도를 수집해서 학습 시킨 결과 60% 정도의 정확도를 얻을 수 있었다. 양도 중요하지만 학습 데이타의 질적인 면도 중요하다.
중복데이타 처리 문제
데이타를 수집해본 결과, 중복되는 데이타가 생각보다 많았다. 중복 데이타를 걸러내기 위해서 파일의 MD5 해쉬 값을 추출해낸 후 이를 비교해서 중복되는 파일을 제거하였는데, 어느정도 효과를 볼 수 있었지만, 아래 이미지와 같이 같은 이미지지만, 편집이나 리사이즈가 된 이미지의 경우에는 다른 파일로 인식되서 중복 체크에서 검출되지 않았다.

연예인 얼굴 인식은 어렵다
얼굴 인식 예제를 만들면서 재미를 위해서 한국 연예인 얼굴을 수집하여 학습에 사용했는데, 제대로 된 학습 데이타를 구하기가 매우 어려웠다. 앞에서 언급한데로 메이크업이나 표정 변화가 너무 심했고, 어렸을때나 나이먹었을때의 차이등이 심했다. 간단한 공부용으로 사용하기에는 좋은 데이타는 아닌것 같다.
그러면 학습에 좋은 데이타는?
그러면 얼굴 인식 학습에 좋은 데이타는 무엇일까? 테스트를 하면서 내린 자체적인 결론은 정면 프로필 사진류가 제일 좋다. 특히 스튜디오에서 찍은 사진은 같은 조명에 같은 메이크업과 헤어스타일로 찍은 경우가 많기 때문에 학습에 적절하다. 또는 동영상의 경우에는 프레임을 잘라내면 유사한 표정과 유사한 각도, 조명등에 대한 데이타를 많이 얻을 수 있기 때문에 좋은 데이타 된다.
얼굴 추출하기
그러면 앞의 내용을 바탕으로 해서, 적절한 학습용 얼굴 이미지를 추출하는 프로그램을 만들어보자
포토샵으로 일일이 할 수 없기 때문에 얼굴 영역을 인식하는 API를 사용하기로한다. OPEN CV와 같은 오픈소스 라이브러리를 사용할 수 도 있지만 구글의 VISION API의 경우 얼굴 영역을 아주 잘 잘라내어주고, 얼굴의 각도나 표정을 인식해서 필터링 하는 기능까지 코드 수십줄만 가지고도 구현이 가능했기 때문에, VISION API를 사용하였다. https://cloud.google.com/vision/
VISION API ENABLE 하기
VISION API를 사용하기 위해서는 해당 구글 클라우드 프로젝트에서 VISION API를 사용하도록 ENABLE 해줘야 한다.
VISION API를 ENABLE하기 위해서는 아래 화면과 같이 구글 클라우드 콘솔 > API Manager 들어간후

+ENABLE API를 클릭하여 아래 그림과 같이 Vision API를 클릭하여 ENABLE 시켜준다.
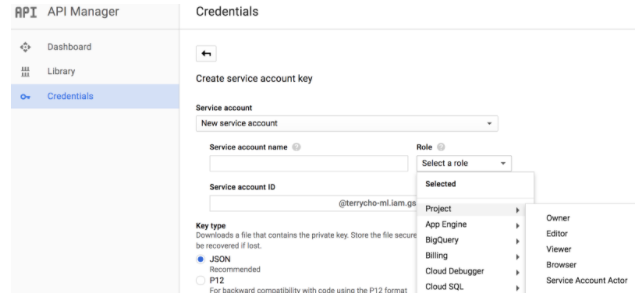
SERVICE ACCOUNT 키 만들기
다음으로 이 VISION API를 호출하기 위해서는 API 토큰이 필요한데, SERVICE ACCOUNT 라는 JSON 파일을 다운 받아서 사용한다.
구글 클라우드 콘솔에서 API Manager로 들어간후 Credentials 메뉴에서 Create creadential 메뉴를 선택한후, Service account key 메뉴를 선택한다

다음 Create Service Account key를 만들도록 하고, accountname과 id와 같은 정보를 넣는다. 이때 중요한것이 이 키가 가지고 있는 사용자 권한을 설정해야 하는데, 편의상 모든 권한을 가지고 있는 Project Owner 권한으로 키를 생성한다.
(주의. 실제 운영환경에서 전체 권한을 가지는 키는 보안상의 위험하기 때문에 특정 서비스에 대한 접근 권한만을 가지도록 지정하여 Service account를 생성하기를 권장한다.)
Service account key가 생성이 되면, json 파일 형태로 다운로드가 된다.
여기서는 terrycho-ml-80abc460730c.json 이름으로 저장하였다.
예제 코드
그럼 예제를 보자 코드의 전문은 https://github.com/bwcho75/facerecognition/blob/master/com/terry/face/extract/crop_face.py 에 있다.
이 코드는 이미지 파일이 있는 디렉토리를 지정하고, 아웃풋 디렉토리를 지정해주면 이미지 파일을 읽어서 얼굴이 있는지 없는지를 체크하고 얼굴이 있으면, 얼굴 부분만 잘라낸 후에, 얼굴 사진을 96x96 사이즈로 리사즈 한후에,
70%의 파일들은 학습용으로 사용하기 위해서 {아웃풋 디렉토리/training/} 디렉토리에 저장하고
나머지 30%의 파일들은 검증용으로 사용하기 위해서 {아웃풋 디렉토리/validate/} 디렉토리에 저장한다.
그리고 학습용 파일 목록은 다음과 같이 training_file.txt에 파일 위치,사람명(라벨) 형태로 저장하고
/Users/terrycho/traning_datav2/training/wsmith.jpg,Will Smith
/Users/terrycho/traning_datav2/training/wsmith061408.jpg,Will Smith
/Users/terrycho/traning_datav2/training/wsmith1.jpg,Will Smith
검증용 파일들은 validate_file.txt에 마찬가지로 파일위치와, 사람명(라벨)을 저장한다.
사용 방법은 다음과 같다.
python com/terry/face/extract/crop_face.py “원본 파일이있는 디렉토리" “아웃풋 디렉토리"
(원본 파일 디렉토리안에는 {사람이름명} 디렉토리 아래에 사진들이 쭈욱 있는 구조라야 한다.)
자 그러면, 코드의 주요 부분을 살펴보자
VISION API 초기화 하기
def __init__(self):
# initialize library
#credentials = GoogleCredentials.get_application_default()
scopes = ['https://www.googleapis.com/auth/cloud-platform']
credentials = ServiceAccountCredentials.from_json_keyfile_name(
'./terrycho-ml-80abc460730c.json', scopes=scopes)
self.service = discovery.build('vision', 'v1', credentials=credentials)
초기화 부분은 Google Vision API를 사용하기 위해서 OAuth 인증을 하는 부분이다.
scope를 googleapi로 정해주고, 인증 방식을 Service Account를 사용한다. credentials 부분에 service account key 파일인 terrycho-ml-80abc460730c.json를 지정한다.
얼굴 영역 찾아내기
다음은 이미지에서 얼굴을 인식하고, 얼굴 영역(사각형) 좌표를 리턴하는 함수를 보자
def detect_face(self,image_file):
try:
with io.open(image_file,'rb') as fd:
image = fd.read()
batch_request = [{
'image':{
'content':base64.b64encode(image).decode('utf-8')
},
'features':[
{
'type':'FACE_DETECTION',
'maxResults':MAX_FACE,
},
{
'type':'LABEL_DETECTION',
'maxResults':MAX_LABEL,
}
]
}]
fd.close()
request = self.service.images().annotate(body={
'requests':batch_request, })
response = request.execute()
if 'faceAnnotations' not in response['responses'][0]:
print('[Error] %s: Cannot find face ' % image_file)
return None
face = response['responses'][0]['faceAnnotations']
label = response['responses'][0]['labelAnnotations']
if len(face) > 1 :
print('[Error] %s: It has more than 2 faces in a file' % image_file)
return None
roll_angle = face[0]['rollAngle']
pan_angle = face[0]['panAngle']
tilt_angle = face[0]['tiltAngle']
angle = [roll_angle,pan_angle,tilt_angle]
# check angle
# if face skew angle is greater than > 20, it will skip the data
if abs(roll_angle) > MAX_ROLL or abs(pan_angle) > MAX_PAN or abs(tilt_angle) > MAX_TILT:
print('[Error] %s: face skew angle is big' % image_file)
return None
# check sunglasses
for l in label:
if 'sunglasses' in l['description']:
print('[Error] %s: sunglass is detected' % image_file)
return None
box = face[0]['fdBoundingPoly']['vertices']
left = box[0]['x']
top = box[1]['y']
right = box[2]['x']
bottom = box[2]['y']
rect = [left,top,right,bottom]
print("[Info] %s: Find face from in position %s and skew angle %s" % (image_file,rect,angle))
return rect
except Exception as e:
print('[Error] %s: cannot process file : %s' %(image_file,str(e)) )
맨 처음에는 얼굴 영역을 추출하기전에, 같은 파일이 예전에 사용되었는지를 확인한다.
image = Image.open(fd)
# extract hash from image to check duplicated image
m = hashlib.md5()
with io.BytesIO() as memf:
image.save(memf, 'PNG')
data = memf.getvalue()
m.update(data)
if image_hash in global_image_hash:
print('[Error] %s: Duplicated image' %(image_file) )
return None
global_image_hash.append(image_hash)
이미지에서 md5 해쉬를 추출한후에, 이 해쉬를 이용하여 학습 데이타로 사용된 파일들의 해쉬와 비교한다. 만약에 중복되는 것이 없으면 이 해쉬를 리스트에 추가하고 다음 과정을 수행한다.
VISION API를 이용하여, 얼굴 영역을 추출하는데, 위의 코드에서 처럼 image_file을 읽은후에, batch_request라는 문자열을 만든다. JSON 형태의 문자열이 되는데, 이때 image라는 항목에 이미지 데이타를 base64 인코딩 방식으로 인코딩해서 전송한다. 그리고 VISION API는 얼굴인식뿐 아니라 사물 인식, 라벨인식등 여러가지 기능이 있기 때문에 그중에서 타입을 ‘FACE_DETECTION’으로 정의하여 얼굴 영역만 인식하도록 한다.
request를 만들었으면, VISION API로 요청을 보내면 응답이 오는데, 이중에서 response 엘리먼트의 첫번째 인자 ( [‘responses’][0] )은 첫번째 얼굴은 뜻하는데, 여기서 [‘faceAnnotation’]을 하면 얼굴에 대한 정보만을 얻을 수 있다. 이중에서 [‘fdBoundingPoly’] 값이 얼굴 영역을 나타내는 사각형이다. 이 갑ㄱㅅ을 읽어서 left,top,right,bottom 값에 세팅한 후 리턴한다.
그리고 얼굴의 각도 (상하좌우옆)를 추출하여, 얼국 각도가 각각 20도 이상 더 돌아간 경우에는 학습 데이타로 사용하지 않고 필터링을 해냈다.
다음은 각도를 추출하고 필터링을 하는 부분이다.
roll_angle = face[0]['rollAngle']
pan_angle = face[0]['panAngle']
tilt_angle = face[0]['tiltAngle']
angle = [roll_angle,pan_angle,tilt_angle]
# check angle
# if face skew angle is greater than > 20, it will skip the data
if abs(roll_angle) > MAX_ROLL or abs(pan_angle) > MAX_PAN or abs(tilt_angle) > MAX_TILT:
print('[Error] %s: face skew angle is big' % image_file)
return None
VISION API에서 추가로 “FACE DETECTION” 뿐만 아니라 “LABEL_DETECTION” 을 같이 수행했는데 이유는 선글라스를 쓰고 있는 사진을 필터링하기 위해서 사용하였다. 아래는 선글라스 있는 사진을 검출하는 코드이다.
# check sunglasses
for l in label:
if 'sunglasses' in l['description']:
print('[Error] %s: sunglass is detected' % image_file)
return None
얼굴 잘라내고 리사이즈 하기
앞의 detect_face에서 필터링하고 찾아낸 얼굴 영역을 가지고 그 부분만 전체 사진에서 잘라내고, 잘라낸 얼굴을 학습에 적합하도록 같은 크기 (96x96)으로 리사이즈 한다.
이런 이미지 처리를 위해서 PIL (Python Imaging Library - http://www.pythonware.com/products/pil/)를 사용하였다.
def crop_face(self,image_file,rect,outputfile):
try:
fd = io.open(image_file,'rb')
image = Image.open(fd)
crop = image.crop(rect)
im = crop.resize(IMAGE_SIZE,Image.ANTIALIAS)
im.save(outputfile,"JPEG")
fd.close()
print('[Info] %s: Crop face %s and write it to file : %s' %(image_file,rect,outputfile) )
except Exception as e:
print('[Error] %s: Crop image writing error : %s' %(image_file,str(e)) )
image_file을 인자로 받아서 , rect 에 정의된 사각형 영역 만큼 crop를 해서 잘라내고, resize 함수를 이용하여 크기를 96x96으로 조정한후 (참고 IMAGE_SIZE = 96,96 로 정의되어 있다.) outputfile 경로에 저장하게 된다.
실행을 해서 정재된 데이타는 다음과 같다.

생각해볼만한점들
이 코드는 간단한 토이 프로그램이기 때문에 간단하게 작성했지만 실제 운영환경에 적용하기 위해서는 몇가지 고려해야 할 사항이 있다.
먼저, 이 코드는 싱글 쓰레드로 돌기 때문에 속도가 상대적으로 느리다 그래서 멀티 쓰레드로 코드를 수정할 필요가 있으며, 만약에 수백만장의 사진을 정재하기 위해서는 한대의 서버로 되지 않기 때문에, 원본 데이타를 여러 서버로 나눠서 처리할 수 있는 분산 처리 구조가 고려되어야 한다.
또한, VISION API로 사진을 전송할때는 BASE64 인코딩된 구조로 서버에 이미지를 직접 전송하기 때문에, 자칫 이미지 사이즈들이 크면 네트워크 대역폭을 많이 잡아먹을 수 있기 때문에 가능하다면 식별이 가능한 크기에서 리사이즈를 한 후에, 서버로 전송하는 것이 좋다. 실제로 필요한 얼굴 크기는 96x96 픽셀이기 때문에 필요없이 1000만화소 고화질의 사진들을 전송해서 네트워크 비용을 낭비하지 않기를 바란다.
다음은 이렇게 정재한 파일들을 텐서플로우에서 읽어서 실제로 학습하는 모델을 만들어보겠다.
위의 코드를 멀티 프로세스&멀티쓰레드로 돌리는 아키텍쳐와 코드는 http://bcho.tistory.com/1177 글을 참고하기 바란다.